Fri 24 Oct 2008
Tags: kvm, linux, centos, virtualisation
Following on from my post yesterday on "Basic KVM on CentOS 5", here's
how to setup simple bridging to allow incoming network connections to
your VM (and to get other standard network functionality like pings
working). This is a simplified/tweaked version of
Hadyn Solomon's bridging instructions.
Note this this is all done on your HOST machine, not your guest.
For CentOS:
# Install bridge-utils
yum install bridge-utils
# Add a bridge interface config file
vi /etc/sysconfig/network-scripts/ifcfg-br0
# DHCP version
ONBOOT=yes
TYPE=Bridge
DEVICE=br0
BOOTPROTO=dhcp
# OR, static version
ONBOOT=yes
TYPE=Bridge
DEVICE=br0
BOOTPROTO=static
IPADDR=xx.xx.xx.xx
NETMASK=255.255.255.0
# Make your primary interface part of this bridge e.g.
vi /etc/sysconfig/network-scripts/ifcfg-eth0
# Add:
BRIDGE=br0
# Optional: comment out BOOTPROTO/IPADDR lines, since they're
# no longer being used (the br0 takes precedence)
# Add a script to connect your guest instance to the bridge on guest boot
vi /etc/qemu-ifup
#!/bin/bash
BRIDGE=$(/sbin/ip route list | awk '/^default / { print $NF }')
/sbin/ifconfig $1 0.0.0.0 up
/usr/sbin/brctl addif $BRIDGE $1
# END OF SCRIPT
# Silence a qemu warning by creating a noop qemu-ifdown script
vi /etc/qemu-ifdown
#!/bin/bash
# END OF SCRIPT
chmod +x /etc/qemu-if*
# Test - bridged networking uses a 'tap' networking device
NAME=c5-1
qemu-kvm -hda $NAME.img -name $NAME -m ${MEM:-512} -net nic -net tap &
Done. This should give you VMs that are full network members, able to be
pinged and accessed just like a regular host. Bear in mind that this means
you'll want to setup firewalls etc. if you're not in a controlled
environment.
Notes:
- If you want to run more than one VM on your LAN, you need to set the
guest MAC address explicitly, since otherwise qemu uses a static default
that will conflict with any other similar VM on the LAN. e.g. do something
like:
# HOST_ID, identifying your host machine (2-digit hex)
HOST_ID=91
# INSTANCE, identifying the guest on this host (2-digit hex)
INSTANCE=01
# Startup, but with explicit macaddr
NAME=c5-1
qemu-kvm -hda $NAME.img -name $NAME -m ${MEM:-512} \
-net nic,macaddr=00:16:3e:${HOST_ID}:${INSTANCE}:00 -net tap &
- This doesn't use the paravirtual ('virtio') drivers that Hadyn mentions,
as these aren't available until kernel 2.6.25, so they're not available
to CentOS linux guests without a kernel upgrade.
Fri 05 Sep 2008
Tags: perl, catalyst, screen
I'm an old-school developer, doing all my hacking using terms, the command
line, and vim, not a heavyweight IDE. Hacking perl
Catalyst projects (and I imagine other
MVC-type frameworks) can be slightly more challenging in this kind of
environment because of the widely-branching directory structure. A single
conceptual change can easily touch controller classes, model classes, view
templates, and static javascript or css files, for instance.
I've found GNU screen to work really
well in this environment. I use per-project screen sessions set up
specifically for Catalyst - for my 'usercss' project, for instance, I have
a ~/.screenrc-usercss config that looks like this:
source $HOME/.screenrc
setenv PROJDIR ~/work/usercss
setenv PROJ UserCSS
screen -t home
stuff "cd ~^Mclear^M"
screen -t top
stuff "cd $PROJDIR^Mclear^M"
screen -t lib
stuff "cd $PROJDIR/lib/$PROJ^Mclear^M"
screen -t controller
stuff "cd $PROJDIR/lib/Controller^Mclear^M"
screen -t schema
stuff "cd $PROJDIR/lib/$PROJ/Schema/Result^Mclear^M"
screen -t htdocs
stuff "cd $PROJDIR/root/htdocs^Mclear^M"
screen -t static
stuff "cd $PROJDIR/root/static^Mclear^M"
screen -t sql
stuff "cd $PROJDIR^Mclear^M"
select 0
(the ^M sequences there are actual Ctrl-M newline characters).
So a:
screen -c ~/.screenrc-usercss
will give me a set of eight labelled screen windows: home, top, lib,
controller, schema, htdocs, static, and sql. I usually run a couple of
these in separate terms, like this:

To make this completely brainless, I also have the following bash function
defined in my ~/.bashrc file:
sc ()
{
SC_SESSION=$(screen -ls | egrep -e "\.$1.*Detached" | \
awk '{ print $1 }' | head -1);
if [ -n "$SC_SESSION" ]; then
xtitle $1;
screen -R $SC_SESSION;
elif [ -f ~/.screenrc-$1 ]; then
xtitle $1;
screen -S $1 -c ~/.screenrc-$1
else
echo "Unknown session type '$1'!"
fi
}
which lets me just do sc usercss, which reattaches to the first detached
'usercss' screen session, if one is available, or starts up a new one.
Fast, flexible, lightweight. Choose any 3.
Wed 20 Aug 2008
Tags: backups, brackup, sysadmin
Further to my earlier post, I've spent a good chunk
of time implementing brackup over the last few weeks, both at home for my
personal backups, and at $work on some really large trees. There are a few
gotchas along the way, so thought I'd document some of them here.
Active Filesystems
First, as soon as you start trying to brackup trees on any size you find
that brackup aborts if it finds a file has changed between the time it
initially walks the tree and when it comes to back it up. On an active
filesystem this can happen pretty quickly.
This is arguably reasonable behaviour on brackup's part, but it gets
annoying pretty fast. The cleanest solution is to use some kind of
filesystem snapshot to ensure you're backing up a consistent view of your
data and a quiescent filesystem.
I'm using linux and LVM, so I'm using LVM snapshots for this, using
something like:
SIZE=250G
VG=VolGroup00
PART=${1:-export}
mkdir -p /${PART}_snap
lvcreate -L$SIZE --snapshot --permission r -n ${PART}_snap /dev/$VG/$PART && \
mount -o ro /dev/$VG/${PART}_snap /${PART}_snap
which snapshots /dev/VolGroup00/export to /dev/VolGroup00/export_snap, and
mounts the snapshot read-only on /export_snap.
The reverse, post-backup, is similar:
VG=VolGroup00
PART=${1:-export}
umount /${PART}_snap && \
lvremove -f /dev/$VG/${PART}_snap
which unmounts the snapshot and then deletes it.
You can then do your backup using the /${PART}_snap tree instead of your
original ${PART} one.
Brackup Digests
So snapshots works nicely. Next wrinkle is that by default brackup writes its
digest cache file to the root of your source tree, which in this case is
readonly. So you want to tell brackup to put that in the original tree, not
the snapshot, which you do in the your ~/.brackup.conf file e.g.
[SOURCE:home]
path = /export_snap/home
digestdb_file = /exportb/home/.brackup-digest.db
ignore = \.brackup-digest.db$
I've also added an explicit ignore rule for these digest files here. You
don't really need to back these up as they're just caches, and they can get
pretty large. Brackup automatically skips the digestdb_file for you, but it
doesn't skip any others you might have, if for instance you're backing up
the same tree to multiple targets.
Synching Backups Between Targets
Another nice hack you can do with brackup is sync backups on
filesystem-based targets (that is, Target::Filesystem, Target::Ftp, and
Target::Sftp) between systems. For instance, I did my initial home directory
backup of about 10GB onto my laptop, and then carried my laptop into where
my server is located, and then rsync-ed the backup from my laptop to the
server. Much faster than copying 10GB of data over an ADSL line!
Similarly, at $work I'm doing brackups onto a local backup server on the
LAN, and then rsyncing the brackup tree to an offsite server for disaster
recovery purposes.
There are a few gotchas when doing this, though. One is that
Target::Filesystem backups default to using colons in their chunk file names
on Unix-like filesystems (for backwards-compatibility reasons), while
Target::Ftp and Target::Sftp ones don't. The safest thing to do is just to
turn off colons altogether on Filesystem targets:
[TARGET:server_fs_home]
type = Filesystem
path = /export/brackup/nox/home
no_filename_colons = 1
Second, brackup uses a local inventory database to avoid some remote
filesystem checks to improve performance, so that if you replicate a backup
onto another target you also need to make a copy of the inventory database
so that brackup knows which chunks are already on your new target.
The inventory database defaults to $HOME/.brackup-target-TARGETNAME.invdb
(see perldoc Brackup::InventoryDatabase), so something like the following
is usually sufficient:
cp $HOME/.brackup-target-OLDTARGET.invdb $HOME/.brackup-target-NEWTARGET.invdb
Third, if you want to do a restore using a brackup file (the
SOURCE-DATE.brackup output file brackup produces) from a different
target, you typically need to make a copy and then update the header
portion for the target type and host/path details of your new target.
Assuming you do that and your new target has all the same chunks, though,
restores work just fine.
Mon 07 Jul 2008
Tags: backups, brackup, sysadmin
I've been playing around with Brad Fitzpatrick's
brackup for the last couple of weeks.
It's a backup tool that "slices, dices, encrypts, and sprays across the
net" - notably to Amazon S3,
but also to filesystems (local or networked), FTP servers, or SSH/SFTP
servers.
I'm using it to backup my home directories and all my image and music
files both to a linux server I have available in a data centre (via
SFTP) and to Amazon S3.
brackup's a bit rough around the edges and could do with some better
documentation and some optimisation, but it's pretty useful as it stands.
Here are a few notes and tips from my playing so far, to save others a
bit of time.
Version: as I write the latest version on CPAN is 1.06, but that's
pretty old - you really want to use the
current subversion trunk
instead. Installation is the standard perl module incantation e.g.
# Checkout from svn or whatever
cd brackup
perl Makefile.PL
make
make test
sudo make install
Basic usage is as follows:
# First-time through (on linux, in my case):
cd
mkdir brackup
cd brackup
brackup
Error: Your config file needs tweaking. I put a commented-out template at:
/home/gavin/.brackup.conf
# Edit the vanilla .brackup.conf that was created for you.
# You want to setup at least one SOURCE and one TARGET section initially,
# and probably try something smallish i.e. not your 50GB music collection!
# The Filesystem target is probably the best one to try out first.
# See '`perldoc Brackup::Root`' and '`perldoc Brackup::Target`' for examples
$EDITOR ~/.brackup.conf
# Now run your first backup changing SOURCE and TARGET below to the names
# you used in your .brackup.conf file
brackup -v --from=SOURCE --to=TARGET
# You can also do a dry run to see what brackup's going to do (undocumented)
brackup -v --from=SOURCE --to=TARGET --dry-run
If all goes well you should get some fairly verbose output about all the files
in your SOURCE tree that are being backed up for you, and finally a brackup
output file (typically named SOURCE-DATE.brackup) should be written to your
current directory. You'll need this brackup file to do your restores, but it's
also stored on the target along with your backup, so you can also retrieve it
from there (using brackup-target, below) if your local copy gets lost, or if
you need to restore to somewhere else.
Restores reference that SOURCE-DATE.brackup file you just created:
# Create somewhere to restore to
mkdir -p /tmp/brackup-restore/full
# Restore the full tree you just backed up
brackup-restore -v --from=SOURCE-DATE.brackup --to=/tmp/brackup-restore/full --full
# Or restore just a subset of the tree
brackup-restore -v --from=SOURCE-DATE.brackup --to=/tmp/brackup-restore --just=DIR
brackup-restore -v --from=SOURCE-DATE.brackup --to=/tmp/brackup-restore --just=FILE
You can also use the brackup-target utility to query a target for the
backups it has available, and do various kinds of cleanup:
# List the backups available on the given target
brackup-target TARGET list_backups
# Get the brackup output file for a specific backup (to restore)
brackup-target TARGET get_backup BACKUPFILE
# Delete a brackup file on the target
brackup-target TARGET delete_backup BACKUPFILE
# Prune the target to the most recent N backup files
brackup-target --keep-backups 15 TARGET prune
# Remove backup chunks no longer referenced by any backup file
brackup-target TARGET gc
That should be enough to get you up and running with brackup - I'll
cover some additional tips and tricks in a subsequent post.
Thu 29 May 2008
Tags: banking, finance, web
Heard via @chieftech on twitter that the
Banking Technology 2008
conference is on today. It's great to see the financial world engaging with
developments online and thinking about new technologies and the Web 2.0 space, but
the agenda strikes me as somewhat weird, perhaps driven mainly by the vendors they
could get willing to spruik their wares?
How, for instance, can you have a "Banking Technology" conference and not have
at least one session on 'online banking'? Isn't this the place where your
technology interfaces with your customers? Weird.
My impression of the state of online banking in Australia is pretty
underwhelming. As a geek who'd love to see some real technology innovation
impact our online banking experiences, here are some wishlist items dedicated
to the participants of Banking Technology 2008. I'd love to see the following:
Multiple logins to an account e.g. a readonly account for downloading
things, a bill-paying account that can make payments to existing vendors,
but not configure new ones, etc. This kind of differentiation would allow
automation (scripts/services) using 'safe' accounts, without having to
put your master online banking details at risk.
API access to certain functions e.g. balance checking, transaction
downloads, bill payment to existing vendors, internal transfers, etc.
Presumably dependent upon having multiple logins (previous), to help
mitigate security issues.
Tagging functionality - the ability to interactively tag transactions (e.g.
'utilities', 'groceries', 'leisure', etc.), and to get those tags included
in transaction reporting and/or downloading. Further, allow autotagging of
transactions via descriptions/type/other party details etc.
Alert conditions - the ability to setup various kinds of alerts on
various conditions, like low or negative balances, large withdrawals,
payroll deposit, etc. I'm not so much thinking of plugging into particular
alert channels here (email, SMS, IM, etc), just the ability to set 'flags'
on conditions.
RSS support - the ability to configure various kinds of RSS feeds of
'interesting' data. Authenticated, of course. Examples: per-account
transaction feeds, an alert condition feed (low balance, transaction
bouncing/reversal, etc.), bill payment feed, etc. Supplying RSS feeds
also means that such things can be plugged into other channels like email,
IM, twitter, SMS, etc.
Web-friendly interfaces - as Eric Schmidt of Google says, "Don't fight the
internet". In the online banking context, this means DON'T use technologies
that work against the goodness of the web (e.g. frames, graphic-heavy design,
Flash, RIA silos, etc.), and DO focus on simplicity, functionality, mobile
clients, and web standards (HTML, CSS, REST, etc.).
Web 2.0 goodness - on the nice-to-have front (and with the proviso that it
degrades nicely for non-javascript clients) it would be nice to see some
ajax goodness allowing more friendly and usable interfaces and faster
response times.
Other things I've missed? Are there banks out there already offering any of
these?
Fri 23 May 2008
Tags: linux, centos, networking
Update 2019-05-05: see this revised post
for a simpler implementation method and a gotcha to watch out for. HT to Jim
MacLeod for suggested improvements in his comments below.
Had to setup some simple policy-based routing on CentOS again recently, and had
forgotten the exact steps. So here's the simplest recipe for CentOS that seems
to work. This assumes you have two upstream gateways (gw1 and gw2), and that
your default route is gw1, so all you're trying to do is have packets that come
in on gw2 go back out gw2.
1) Define an extra routing table e.g.
$ cat /etc/iproute2/rt_tables
#
# reserved values
#
255 local
254 main
253 default
0 unspec
#
# local tables
#
102 gw2
#
2) Add a default route via gw2 (here 172.16.2.254) to table gw2 on the
appropriate interface (here eth1) e.g.
$ cat /etc/sysconfig/network-scripts/route-eth1
default table gw2 via 172.16.2.254
3) Add an ifup-local script to add a rule to use table gw2 for eth1 packets e.g.
$ cat /etc/sysconfig/network-scripts/ifup-local
#!/bin/bash
#
# Script to add/delete routing rules for gw2 devices
#
GW2_DEVICE=eth1
GW2_LOCAL_ADDR=172.16.2.1
if [ $(basename $0) = ifdown-local ]; then
OP=del
else
OP=add
fi
if [ "$1" = "$GW2_DEVICE" ]; then
ip rule $OP from $GW2_LOCAL_ADDR table gw2
fi
4) Use the ifup-local script also as ifdown-local, to remove that rule
$ cd /etc/sysconfig/network-scripts
$ ln -s ifup-local ifdown-local
5) Restart networking, and you're done!
# service network restart
For more, see:
Mon 21 Apr 2008
Tags: fire eagle, location, web, microformats
I've been thinking about Yahoo's new fire eagle
location-broking service over the last few days. I think it is a really
exciting service - potentially a game changer - and has the potential to
move publishing and using location data from a niche product to something
really mainstream. Really good stuff.
But as I posted here, I also think fire
eagle (at least as it's currently formulated) is probably only usable by
a relatively small section of the web - roughly the relatively
sophisticated "web 2.0" sites who are comfortable with web services and api
keys and protocols like OAuth.
For the rest of the web - the long web 1.0 tail - the technical bar is
simply too high for fire eagle as it stands to be useful and usable.
In addition, fire eagle as it currently stands is unicast, acting as a
mediator between you some particular app acting as a producer or a consumer
of your location data. But, at least on the consumer side, I want some kind
of broadcast service, not just a per-app unicast one. I want to be able to
say "here's my current location for consumption by anyone", and allow that
to be effectively broadcast to anyone I'm interacting with.
Clearly my granularity/privacy settings might be different for my public
location, and I might want to be able to blacklist certain sites or parties
if they prove to be abusers of my data, but for lots of uses a broadcast
public location is exactly what I want.
How might this work in the web context? Say I'm interacting with an
e-commerce site, and if they some broad idea of my location (say,
postcode, state, country) they could default shipping addresses for me,
and show me shipping costs earlier in the transaction (subject to change,
of course, if I want to ship somewhere else). How can I communicate my
public location data to this site?
So here's a crazy super-simple proposal: use Microformat HTTP Request
Headers.
HTTP Request Headers are the only way the browser can pass information
to a website (unless you consider cookies a separate mechanism, and they
aren't really useful here because they're domain specific). The
HTTP spec
even carries over the
"From"
header from email, to allow browsers to communicate who the user is to
the website, so there's some kind of precedent for using HTTP headers for
user info.
Microformats are useful here because they're
really simple, and they provide useful standardised vocabularies around
addresses (adr) and geocoding
(geo).
So how about (for example) we define a couple of custom HTTP request
headers for public location data, and use some kind of microformat-inspired
serialisation (like e.g. key-value pairs) for the location data? For
instance:
X-Adr-Current: locality=Sydney; region=NSW; postal-code=2000; country-name=Australia
X-Geo-Current: latitude=33.717718; longitude=151.117158
For websites, the usage is then about as trivial as possible: check for
the existence of the HTTP header, do some very simple parsing, and use
the data to personalise the user experience in whatever ways are
appropriate for the site.
On the browser side we'd need some kind of simple fire eagle client that
would pull location updates from fire eagle and then publish them via
these HTTP headers. A firefox plugin would probably be a good proof of
concept.
I think this is simple, interesting and useful, though it obviously
requires websites to make use of it before it's of much value in the real
world.
So is this crazy, or interesting?
Tue 15 Apr 2008
Tags: location, fire eagle, web, web2.0
Brady Forrest asked in a recent
post
what kinds of applications people would most like to see working with Yahoo's
new location-broking service Fire Eagle (currently
in private beta).
It's clear that most of the shiny new web 2.0 sites and apps might be able to
benefit from such personal location info:
photo sites that can do automagic geotagging
calendar apps that adapt to our current timezone
search engines that can take proximity into account when weighting results
social networks that can show us people in town when we're somewhere new
maps and mashups that start where you are, rather than with some static default
etc.
And such sites and apps will no doubt be early adopters of fire eagle and
whatever other location brokers might bubble up in the next little while.
Two things struck me with this list though. First, that's a lot of sites and
apps right there, and unless the friction of authorising new apps to have
access to my location data is very low, the pain of micromanaging access is
going to get old fast. Is there some kind of 'public' client level access in
fire eagle that isn't going to require individual app approval?
Second, I can't help thinking that this still leaves most of the web out in
the cold. Think about all the non-ajax sites that you interact with doing
relatively simple stuff that could still benefit from access to your public
location data:
the shipping address forms you fill out at every e-commerce site you buy from
store locators and hours pages that ask for a postcode to help you (every time!)
timetables that could start with nearby stations or routes or lines if they
knew where you were
intelligent defaults or entry points for sites doing everything from movie
listings to real estate to classifieds
This is the long tail of location: the 80% of the web that won't be using ajax
or comet or OAuth or web service APIs anytime soon. I'd really like my location
data to be useful on this end of the web as well, and it's just not going to
happen if it requires sites to register api keys and use OAuth and make web
service api calls. The bar is just too high for lots of casual web developers,
and an awful lot of the web is still custom php or asp scripts written by
relative newbies (or maybe that's just here in Australia!). If it's not almost
trivially easy, it won't be used.
So I'm interested in how we do location at this end of the web. What do we
need on top of fire eagle or similar services to make our location data
ubiquitous and immediately useful to relatively non-sophisticated websites?
How do we deal with the long tail?
Wed 09 Apr 2008
Tags: web, perl
I've been playing around with SixApart's
TheSchwartz for the last few days.
TheSchwartz is a lightweight reliable job queue, typically used for
handling relatively high latency jobs that you don't want to try and
handle from a web process e.g. for sending out emails, placing orders
into some external system, etc. Basically interacting with anything
which might be down or slow or which you don't really need right away.
Actually, TheSchwartz is a job queue library rather than a job queue
system, so some assembly is required. Like most Danga/SixApart
software, it's lightweight, performant, and well-designed, but also
pretty light on documentation. If you're not comfortable reading the
(perl) source, it might be a challenging environment to setup.
Notes from the last few days:
Don't use the version on CPAN, get the latest code from
subversion
instead. At the moment the CPAN version is 1.04, but current
svn is at 1.07, and has some significant additional
functionality.
Conceptually TheSchwartz is very simple - jobs with opaque
function names and arguments are inserted into a database
for workers with a particular 'ability'; workers periodically
check the database for jobs matching the abilities they have,
and grab and execute them. Jobs that succeed are marked
completed and removed from the queue; jobs that fail are
logged and left on the queue to be retried after some time
period up to a configurable number of retries.
TheSchwartz has two kinds of clients - those that submit
jobs, and workers that perform jobs. Both are considered
clients, which is confusing if you're thinking in terms of
client-server interaction. TheSchwartz considers both
sides to be clients.
There are three main classes to deal with: TheSchwartz,
which is the main client functionality class;
TheSchwartz::Job, which models the jobs that are submitted
to the job queue; and TheSchwartz::Worker, which is a
role-type class modelling a particular ability that a worker
is able to perform.
New worker abilities are defined by subclassing
TheSchwartz::Worker and defining your new functionality in
a work() method. work() receives the job object from the
queue as its only argument and does its stuff, marking the
job as completed or failed after processing. A useful real
example worker is TheSchwartz::Worker::SendEmail (also by
Brad Fitzpatrick, and available on CPAN) for sending emails from
TheSchwartz.
Depending on your application, it may make sense for workers
to just have a single ability, or for them to have multiple
abilities and service more than one type of job. In the latter
case, TheSchwartz tries to use unused abilities whenever it
can to avoid certain kinds of jobs getting starved.
You can also subclass TheSchwartz itself to modify the standard
functionality, and I've found that useful where I've wanted more
visibility of what workers are doing that you get out of the box.
You don't appear at this point to be able to subclass
TheSchwartz::Job however - TheSchwartz always uses this as the
class when autovivifying jobs for workers.
There are a bunch of other features I haven't played with yet,
including job priorities, the ability to coalesce jobs into
groups to be processed together, and the ability to delay jobs
until a certain time.
I've actually been using it to setup a job queue system for a cluster,
which is a slightly different application that it was intended for,
but so far it's been working really well.
I'm still feeling like I'm still getting to grips with the breadth
of things it could be used for though - more experimentation required.
I'd be interested in hearing of examples of what people are using it
for as well.
Recommended.
Thu 27 Mar 2008
Tags: perl, tips
I wasted 15 minutes the other day trying to remember how to do this,
so here it is for the future: to find out if and when a perl module
got added to the core, you want Richard Clamp's excellent
Module::CoreList.
Recent versions have a 'corelist' frontend command, so I typically
use that e.g.
$ corelist File::Basename
File::Basename was first released with perl 5
$ corelist warnings
warnings was first released with perl 5.006
$ corelist /^File::Spec/
File::Spec was first released with perl 5.00405
File::Spec::Cygwin was first released with perl 5.006002
File::Spec::Epoc was first released with perl 5.006001
File::Spec::Functions was first released with perl 5.00504
File::Spec::Mac was first released with perl 5.00405
File::Spec::OS2 was first released with perl 5.00405
File::Spec::Unix was first released with perl 5.00405
File::Spec::VMS was first released with perl 5.00405
File::Spec::Win32 was first released with perl 5.00405
$ corelist URI::Escape
URI::Escape was not in CORE (or so I think)
Wed 19 Mar 2008
Tags: blosxom, nagios
A little whole ago at one of my client sites we decided that we wanted to
monitor the bulk of our Nagios notifications via RSS
rather than via email or jabber. The centralised river-of-news architecture
of RSS is just a much better fit for high-volume notification flow than the
individual silos and persistent messaging nature of email.
There are a few nice RSS solutions out there for Nagios, including the
following:
We quite liked Altinity's RSS4NAGIOS because it was notifications (rather than
alerts) based, and because it was pretty easy to just drop in and use. The
only thing we didn't really like was that it was still relatively static - it
provides nice per-user feeds, but you can't carve those feeds up or drill down
to subsets of the data very easily. We wanted to be able to slice-and-dice
things a bit more dynamically - be able to look at feeds for per-host,
per-hostgroup, per-status, or date-filtered notifications, for example.
I'm also a blosxom developer, so I quickly
realised that I could do everything I wanted pretty trivially using blosxom.
All I needed was a script to capture and tag notifications as blosxom posts,
and then I could have dynamic filtering, multi-dimensional tag-based feeds,
etc., all pretty much for free.
So a couple of afternoons later, Blosxom4Nagios was up and running. It's
basically a single-purpose blosxom install that you drop into a directory
somewhere (/var/log/nagios/blosxom, by default), hook into apache for
display, hook into nagios to accept notifications, and away you go.
Notifications are tagged by type (host/service), state (OK, WARNING, CRITICAL
etc.), hostname, hostgroup, service name, service group, contact, and date,
so you can filter notifications based on any of these, and produce feeds (both
RSS2 and atom) on any of them as well e.g.
etc.
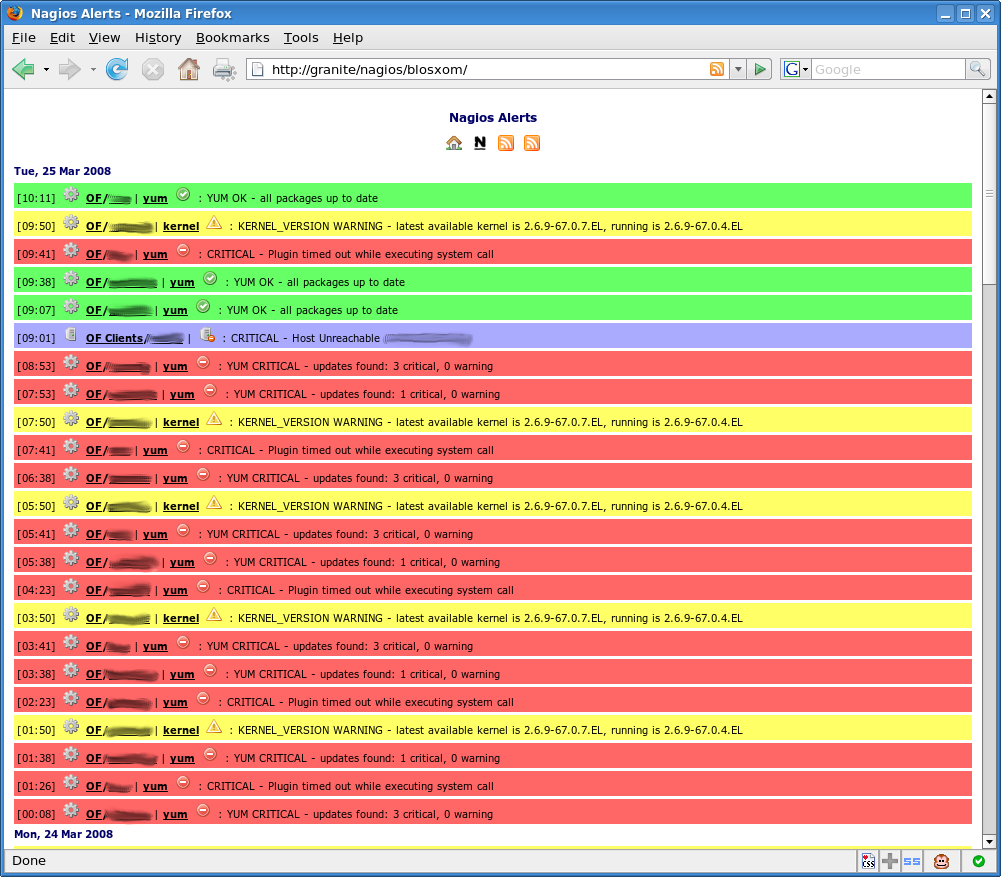
Screenshots:
 Default View
Default View
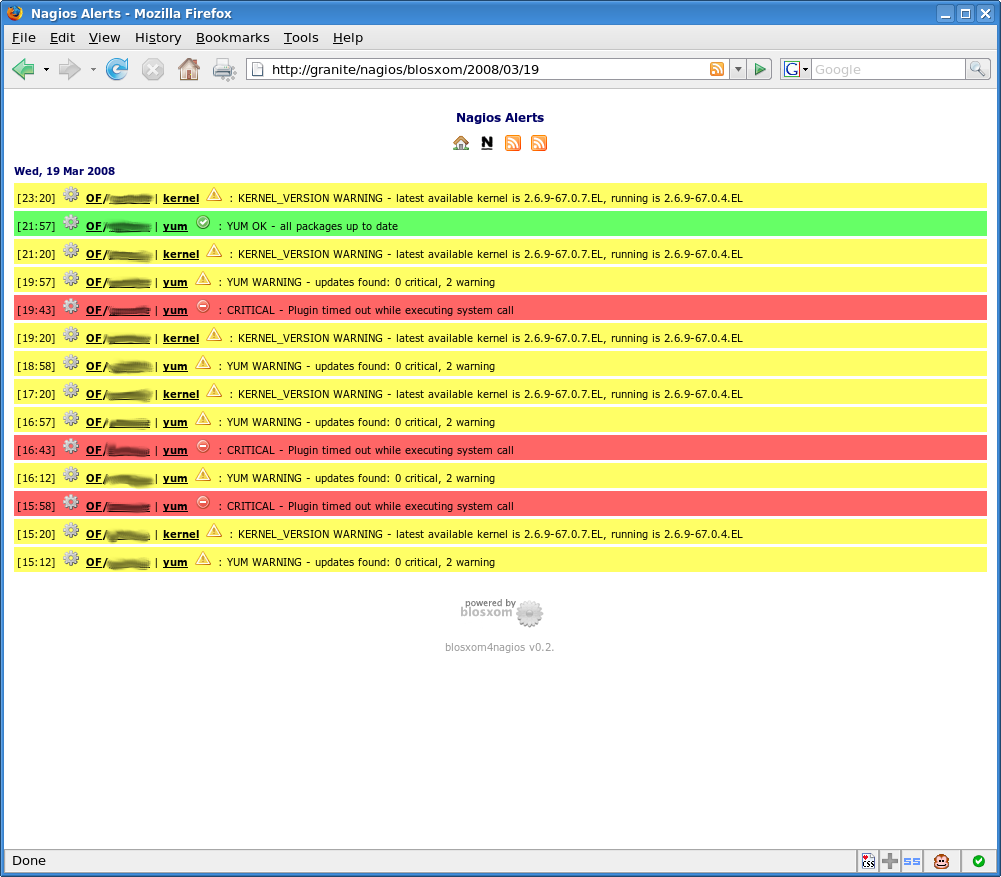
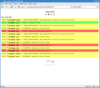 Filtering by date
Filtering by date
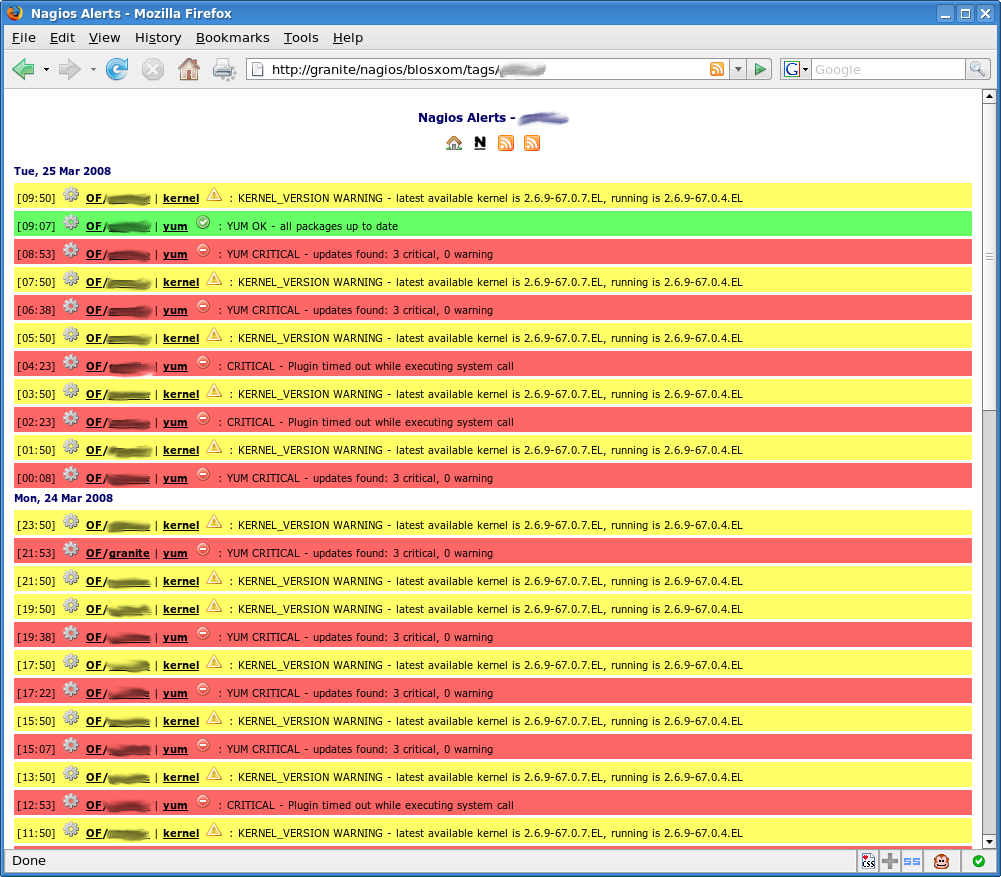
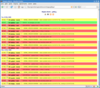 Filtering by host
Filtering by host
Blosxom4Nagios is available here:
and is licensed under the same MIT Licence as blosxom itself.
Comments and feedback welcome.
Mon 17 Mar 2008
Tags: perl
Saw this post fly past in the twitter stream today:
"http://linuxshellaccount.blogspot.com/2008/03/perl-directory-permissions-difference.html".
It's a script by Mike Golvach to do something like a `diff -r`, but also
showing differences in permissions and ownership, rather than just content.
I've written a CPAN module to do stuff like this -
File::DirCompare - so
thought I'd check how straightforward this would be using File::DirCompare:
#!/usr/bin/perl
use strict;
use File::Basename;
use File::DirCompare;
use File::Compare qw(compare);
use File::stat;
die "Usage: " . basename($0) . " dir1 dir2\n" unless @ARGV == 2;
my ($dir1, $dir2) = @ARGV;
File::DirCompare->compare($dir1, $dir2, sub {
my ($a, $b) = @_;
if (! $b) {
printf "Only in %s: %s\n", dirname($a), basename($a);
} elsif (! $a) {
printf "Only in %s: %s\n", dirname($b), basename($b);
} else {
my $stata = stat $a;
my $statb = stat $b;
# Return unless different
return unless compare($a, $b) != 0 ||
$stata->mode != $statb->mode ||
$stata->uid != $statb->uid ||
$stata->gid != $statb->gid;
# Report
printf "%04o %s %s %s\t\t%04o %s %s %s\n",
$stata->mode & 07777, basename($a),
(getpwuid($stata->uid))[0], (getgrgid($stata->gid))[0],
$statb->mode & 07777, basename($b),
(getpwuid($statb->uid))[0], (getgrgid($statb->gid))[0];
}
}, { ignore_cmp => 1 });
So this reports all entries that are different in content or permissions or
ownership e.g. given a tree like this (slightly modified from Mike's
example):
$ ls -lR scripts1 scripts2
scripts1:
total 28
-rw-r--r-- 1 gavin gavin 0 Mar 17 16:41 script1
-rw-r--r-- 1 gavin gavin 0 Mar 17 16:41 script1.bak
-rw-r--r-- 1 gavin gavin 0 Mar 17 16:41 script2
-rw-r--r-- 1 gavin gavin 0 Mar 17 16:41 script2.bak
-rw-r--r-- 1 gavin gavin 0 Mar 17 16:41 script3
-rw-r--r-- 1 gavin gavin 0 Mar 17 16:41 script3.bak
-rw-r--r-- 1 gavin gavin 0 Mar 17 16:49 script4
scripts2:
total 28
-rw-r--r-- 1 gavin users 0 Mar 17 16:41 script1
-rw-r--r-- 1 gavin users 0 Mar 17 16:41 script1.bak
-rw-r--r-- 1 gavin gavin 0 Mar 17 16:41 script2
-rw-r--r-- 1 gavin gavin 0 Mar 17 16:41 script2.bak
-rwxr-xr-x 1 gavin gavin 0 Mar 17 16:41 script3*
-rwxr-xr-x 1 gavin gavin 0 Mar 17 16:41 script3.bak*
-rw-r--r-- 1 gavin gavin 0 Mar 17 16:49 script5
it will give output like the following:
$ ./pdiff2 scripts1 scripts2
0644 script1 gavin gavin 0644 script1 gavin users
0644 script1.bak gavin gavin 0644 script1.bak gavin users
0644 script3 gavin gavin 0755 script3 gavin gavin
0644 script3.bak gavin gavin 0755 script3.bak gavin gavin
Only in scripts1: script4
Only in scripts2: script5
This obviously has dependencies that Mike's version doesn't have, but it
comes out much shorter and clearer, I think. It also doesn't fork and parse
an external ls, so it should be more portable and less fragile. I should
probably be caching the getpwuid lookups too, but that would have made it
5 lines longer. ;-)
Wed 05 Mar 2008
Tags: billing, finance, web
Was thinking in the weekend about places where I waste time, areas of
inefficiency in my extremely well-ordered life (cough splutter).
One of the more obvious was bill handling. I receive paper bills during
the month from the likes of Energy Australia, Sydney Water, David Jones,
our local council for rates, etc. These all go into a pending file in the
filing cabinet, in date order, and I then periodically check that file
during the month and pay any bills that are coming due. If I get busy or
forgetful I may miss a due date and pay a bill late. If a bill gets lost
in the post I may not pay it at all. And the process is all dependent on
me polling my billing file at some reasonable frequency.
There are variants to this process too. Some of my friends do all their
bills once a month, and just queue the payments in their bank accounts
for future payment on or near the due date. That's a lower workload
system than mine, but for some (mostly illogical) reason I find myself
not really trusting future-dated bill payments in the same way as
immediate ones.
There's also a free (for users) service available in Australia called
BPay View
which allows you to receive your bills electronically directly into your
internet banking account, and pay them from there. This is nice in that
it removes the paper and data entry pieces of the problem, but it's
still a pull model - I still have to remember to check the BPay View
page periodically - and it's limited to vendors that have signed up for
the program.
As I see it, there are two main areas of friction in this process:
using a pull model i.e. the process all being dependent on me
remembering to check my bill status periodically and pay those that
are coming due. My mental world is quite cluttered enough without
having to remember administrivia like bills.
the automation friction around paper-based or PDF-based bills,
and the consequent data entry requirements, the scope for user
errors, etc.
BPay View mostly solves the second of these, but it's a solution that's
closely coupled with your Internet Banking provider. This has security
benefits, but it also limits you to your Internet Banking platform. For
me, the first of these is a bigger issue, so I'd probably prefer a
solution that was decoupled from my internet banking, and accept a few
more issues with #2.
So here's what I want:
a billing service that receives bills from vendors on my behalf
and enters them into its system. Ideally this is via email (or even
a web service) and an XML bill attachment; in the real world it
probably still involves paper bills and data entry for the short to
medium term.
a flexible notification system that pushes alerts to me when bills
are due based on per-vendor criteria I configure. This should
include at least options like email, IM, SMS, twitter, etc.
Notifications could be fire-once or fire-until-acknowledged, as the
user chooses.
for bonus points, an easy method of transferring bills into my
internet banking. The dumb solution is probably just a per-bill
view from which I can cut and paste fields; smarter solutions
would be great, but are probably dependent on the internet
banking side. Or maybe we do some kind of per-vendor pay online
magic, if it's possible to figure out the security side of not
storing credit card info. Hmmm.
That sounds pretty tractable. Anyone know anything like this?
Mon 03 Mar 2008
Tags: tips, linux
Find goodness (with a recent-ish find for the '-delete'):
find -L . -type l
find -L . -type l -delete
Sun 10 Feb 2008
Tags: hardware, mp3, ogg vorbis
Bought a new car stereo a few weeks ago to replace the broken
CD-stacker that came with our Ford Fairmont.
In researching the options it seemed that the mainstream
choices these days were for stereos with auxiliary-in jacks
at the front, so you could plug your music player in, and/or
units that would play mp3s. Turns out that latter option
means they will play mp3s that you've burned onto CDs, not
off something super-high-tech like a memory stick. Hmmm.
Well, that's not quite true. Newer units are starting to
appear with USB slots that will play music off a USB memory
stick, so there are actually starting to be some useful
options available. I didn't see any that took anything like
compact flash or SD cards however.
They also don't seem to know anything much about codecs
except MP3, WMA, WAV, and some AAC. Being the open source
geek that I am, I was keen to get something that supported
ogg vorbis, but I
could not find any information (including with my google-fu)
on models that might support this. I did find one guy, however,
who'd burnt a bunch of tracks in different formats to a CD
and then just gone down and tried out all the units at his
local hi-fi store. That sounded like a plan!
So I ended up testing a bunch of units at my local JB Hi-Fi
and Strathfield stores, and the good news is that about half
of them actually played ogg vorbis just fine. I guess they're
just using stock sound decoder chips, which these support a
whole bunch of codecs out of the box. Sure would be nice if
they could manage to advertise the codecs they actually
support though.
We ended up going with a
Kenwood KDC-MP4036U,
which advertises support for "MP3/WMA/AAC Files", but
plays at least ogg vorbis just fine as well. It's supposedly
AU$429 RRP, but we picked it up for $180 at the big
post-Christmas sale at
Strathfield,
so clearly it pays to shop around.
So far it's working really nicely - I've got most of the
girls' music and stories on a 4GB USB stick and get them to
drive the music selection from the back using the remote
control. Way more music than 6-CDs ever gave us, and
without the hassle of a separate music player or ipod.
All is good in the car again!
Wed 23 Jan 2008
Tags: bookmarks, amazon, web service, music, cover art
Very cool. Was just looking for a way of finding cover art for my
ripped music collection, and came across this site:
This is part of the Jiboneus Amazon Web Services project, and lets
you search for cover art and album details on Amazon via their web
services interface. More kudos to Amazon for providing an open
ecosystem for this kind of stuff to grow.
Wed 16 Jan 2008
Tags: css, user css, user styles
I've been messing with user stylesheets the last couple of days, almost
getting what I want, but not quite.
I'm a happy little firefox user, but the stock firefox functionality in
this area really isn't that useful. My gripes:
first, firefox/mozilla seems to only support a single global user
stylesheet, which gets huge and unwieldy awfully fast. Opera does
this much better than firefox, I hear.
because of this, to apply styles to a particular site you have to use
a magic @-moz-document domain style modifier, and this doesn't
seem to play nicely with @media modifiers, so afaict there doesn't seem
to be a way of specifying print styles for a particular site, say.
If I'm wrong about this, I'd be happy to hear about it.
user stylesheets are local files, which means they don't follow me around
across the different machines I use, and I don't get any
network effects from the work of others, as is available using a
'cloud' solution like greasemonkey
(more minor) I know it's to spec, but having to specify !important
everywhere to force user styles to stick gets old fast
As usual with firefox, there's an extension/add-on that does the job
better though. The Stylish
extension - "Stylish is to CSS what Greasemonkey is to JavaScript" - does
a pretty nice job of addressing (1) and some of (3) above (the network
effects part), allowing you to import and manage multiple per-site
stylesheets pretty nicely.
My other quibbles remain, though. In particular, there doesn't seem to be
a nice way of setting up media-specific per-site styles, which is a must-have,
I think. I'd also really love a solution that would follow me across browsers,
especially given the number of sites you might want to tweak is typically much
larger than the number of extensions you typically have installed.
Hmmmm.
Thu 10 Jan 2008
Tags: jabber, xmpp, twitter
From the quick-hack-department: I'm online for most of the day,
and almost always have one or two instant messaging (IM) clients
open - most often [pidgin/gaim](
http://www.pidgin.im/) and
[gajim](
http://www.gajim.org/) lately. I also use IM to
follow
twitter and to tweet.
Now graphical clients are very nice for lots of uses, but one thing
they're often not good at is packing info into less space.
Depending on how many people you're following, twitter in particular
can get noisy fast, and I found myself really wanting a command-line
xmpp client that I could just leave open in a term out of the way
and use as a river-of-news style xmpp stream. Even read-only would
be fine, since I could always pull up my graphical client to tweet
(and I'm a
twit, not a twerp).
Google turned up a few candidates, but nothing really had my use
case in mind. So a couple of hours later, the first version of
clix was born. It's a quick perl script using
Net::XMPP2,
and is available here:
- "http://www.openfusion.com.au/labs/dist/clix"
- "http://www.openfusion.com.au/labs/dist/clix-0.001004.tar.gz"
- "http://www.openfusion.com.au/mrepo/centos5-i386/RPMS.of/clix-0.001004-1.of.noarch.rpm"
It aggregates XMPP posts from any number of accounts into a single
river-of-news style view, and is (currently at least) read-only
i.e. there's no post capability.
Update: updated to version 0.001004 with Yoshizumi's fix from
comments.
Fri 28 Dec 2007
Tags: djabberd, jabber, xmpp
Just started some serious playing with djabberd,
Danga's pluggable XMPP/Jabber server.
At this stage it's almost more a toolkit than an out-of-the-box jabber server,
but it's pretty fun. I'm running the
subversion trunk version,
running than the older version on CPAN.
Documentation is pretty sparse though, so thought I'd collate the resources I've
found useful so far:
So far I've got an RPM for CentOS 5 of the svn trunk code, and am running it
in test mode at a couple of places. I've got LDAP auth, rosters, and vcards
working well, and am still working on offline storage, multi-user chat, and
bot integration. I'll post the RPM and some example configs when I'm a little
further along.
Thu 27 Dec 2007
Tags: web, rss
As the use of RSS and Atom becomes increasingly widespread (we have people
talking about Syndication-Oriented Architecture now), it seems to me that
one of the use cases that isn't particularly well covered off is transient
or short-term feeds.
In this category are things like short-term blogs (e.g. the feeds on the
advent blogs I was reading this year:
Catalyst 2007 and
24 Ways 2007), or comment feeds, for tracking the
comments on a particular post.
Transient feeds require at least the ability to auto-expire a feed after
some period of time (e.g. 30 days after the last entry) or after a certain
date, and secondarily, the ability to add feeds almost trivially to your
newsreader (I'm currently just using the thunderbird news reader, which
is reasonable, but requires about 5 clicks to add a feed).
Anyone know of newsreaders that offer this functionality?